 |
The “human to bot” style experience is the least exciting way to build with LLMs, but it’s by far the most prevalent integration pattern.
There is a difference between the UI representation we call a “chatbot” and the integration pattern behind the scenes. Chatbots are terrible, but that’s a post for another day. In this instance, I’m talking about the integration pattern of going straight from human-entered content to a non-deterministic bot, like an LLM, and back again. “Human to bot” is how companies build most LLM-driven apps today, but there are better ways.
If you think of generative AI tools or experiences, the first thing that comes to mind is likely a ChatGPT-style chat experience—one where you type or speak a prompt into a box and get some text, an image, or maybe a video generated in response. OpenAI’s May 2024 announcement of a multi-modal model supporting real-time video and audio blurred the lines slightly. Still, the general principle remains: A human prompt enters a mystery box, and something else emerges. And importantly, something different could come out each time, even if you start with the same prompt.

The “human to bot” style app is the most natural place to start exploring large language models for two unrelated reasons: evolution and simplicity.
Evolution: from attention to Claude
We can look to the recent past to understand why chat is a natural place to crawl before running with LLMs. In 2019, GPT-2, a predecessor to the ChatGPT we have today, was explicitly trained as a prediction engine that could generate “coherent paragraphs of text” and “predict the next word, given all of the previous words within some text.” So, if we think of it as a word association game, if we say “apple,” we’d expect it to say something like “banana” in response.
This back-and-forth volley between human and computer sounds awfully similar to auto-completion. Not-so-coincidentally, completion is a keyword in the structure of the prominent APIs for building with different large language models, including Claude, Mistral, and ChatGPT.
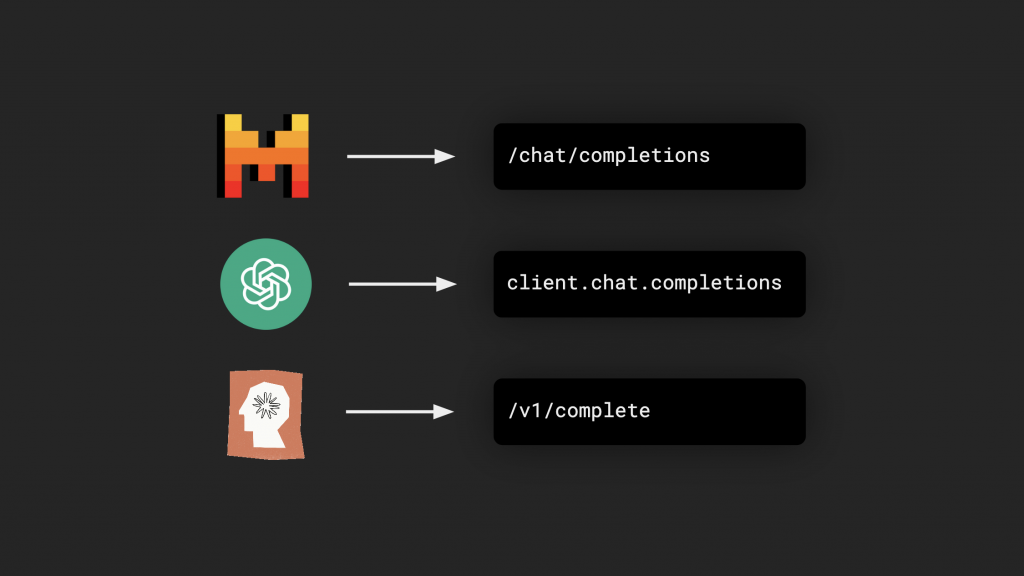
The idea of progressively accurate and intelligent auto-completion is inspiring work, but it’s impossible to ignore that we’re starting from a disembodied anthropomorphized experience. One where, just a few short years later, we now find that giving an LLM a persona may improve the accuracy and reliability of the response. When natural language text is the first input, the “human to bot” evolution makes sense.
Simplicity: building close to the metal
As developers, architects, and senior leaders, we’re constantly bombarded on all sides by the “new.” A new framework. New languages. New ways of organizing our teams. And nowhere is that problem more acute than the swirling conversation around “Artificial Intelligence.”
Fear, uncertainty, and doubt about AI, what it can do, and what it will do (or what we’ll do with it) have permeated every company I’ve talked to in the last couple of years. We can see the result firsthand by looking at the staggering number of companies rebranding as “AI first” without changing anything.
Trying to ride the hype wave with a puddle-depth rebrand has actual costs. It muddies the water, distracts from the innovative work pushing us forward, and relegates the potential to a mere toy in public opinion. But most importantly for us, it crowds out the marketplace with hundreds of products we need to evaluate and choose from, some of which feel like they were just AI-generated themselves.
Many of us find ourselves in a position where we help choose boring technology for our companies and teams. Still, how do we do that when we don’t fully understand the technology’s failure modes yet, and the marketplace is crowded with tools that just wrap LLMs?
Go simple. Go straight to the only trusted technology—the LLM. In a noisy marketplace, sometimes the best thing we can do is skip the middleman and go to the manufacturer directly. This tight coupling is simple, just an API call, and it’s as close to the metal as many of us can get with LLMs. This simplicity means that a “human to bot” style app is an excellent place to get our feet wet, but it’s not a pattern that will revolutionize our work for long.
Gaps in direct-to-LLM integrations
Almost two years into official API access for ChatGPT, cracks are becoming more evident in the direct-to-LLM integration pattern as more and more businesses turn to AI for their next evolution. Companies need a sustainable competitive advantage—a moat. But AI is not a moat, especially for startups. Enterprises may succeed more in building an applied ML/AI strategy, but only because they have the luxury of data, at which point data continues to be the moat more than AI.
But the direct-to-LLM experiences are alluring. They’re simple to build and rapidly demonstrate the power of an LLM coupled with a specific business domain. They make for a good demo, but we quickly run into some constraints and tradeoffs:
- Limited information: Not necessarily context tokens. Details into the business, the person interacting with the machine, each API that provides some small amount of data, and so on. Even with theoretical infinite context, the LLM doesn’t necessarily know how or where to get the information it needs without significant input.
- Unwarranted trust: Interacting with a non-deterministic program is a relatively novel concept. For decades, we’ve nearly exclusively used tools where if you type into a box, it does the same thing every single time. That’s no longer necessarily the case, and it’s a paradigm shift that can cause users to trust the output (or what’s happening with the data they put in) more than they should.
- Monotonous experiences: Let’s be honest; there are only so many exciting and valuable ways to incorporate a chat experience into a UI.
- Poor governance: Deploying AI or LLM-driven experiences to production without proper governance is irresponsible. The experiences we build with LLMs are no less governable than any other, albeit more complex. Going directly to and from an LLM in an experience removes our opportunity to inject governance into the input and output on either side of the large language model.
When all you have is a hammer, everything looks like a nail.
When all you have is an LLM, everything looks like a chatbot.
Other integration patterns
There are many other patterns and ways to build out there, these are just the ones I’ve used in the tools and products I’ve been building and experimenting with. Each deserves a full-length post, so all I’ve done here is capture the intent behind the pattern and provide a brief description of what it helps solve. Not all patterns below solve all of the constraints we see with the direct-to-LLM route, but each of them shifts the trade-offs in a different way.
It’s easier to reason about abstract topics like integration patterns with names we’re more familiar with daily. At the risk of oversimplifying, I’ve used a food preparation theme for these patterns, reminiscent of the late Aaron Swartz’s take on pages generated by a CMS. I think it nicely encapsulates the area in the architecture at which we make decisions, adjust responses, or add controls in the process.
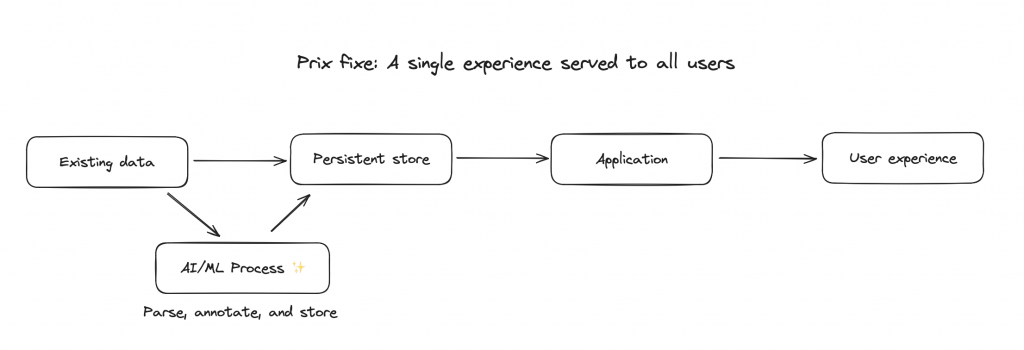
Prix fixe: A single experience served to all users
Use an LLM, or if you’re feeling old-school, just a machine learning model, to parse some data and create a limited set of interesting options to present to all users. An excellent example of this is on LinkedIn when they make “AI suggestions” below a post (note the little ✨buttons in the image below).
In this pattern, we have an opportunity to validate and course-correct responses before the experience goes out to the user.
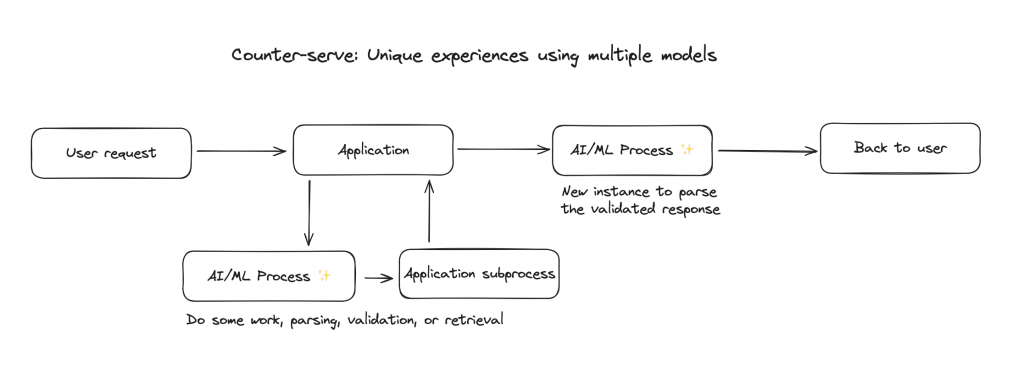
Counter-serve: Unique experiences using multiple models
Like your favorite Chipotle or Which Wich, the counter-serve integration pattern passes data to and from multiple models and controls before it eventually reaches the user. For example, use an LLM to decide which pre-defined action to take based on a message sent by a user, then do some work and use a new instance of an LLM to synthesize the safe and parsed information back to the user.
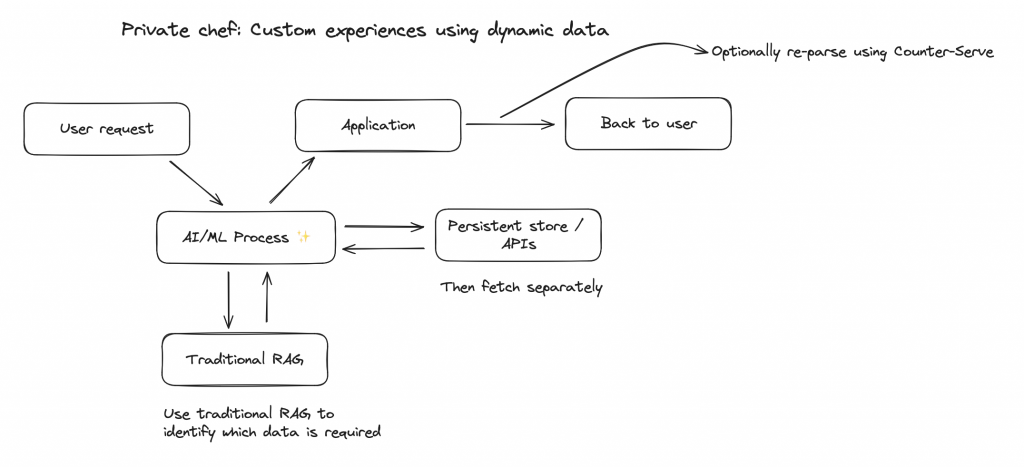
Private chef: Custom experiences using dynamic data
Perpetually training models on dynamic data is unrealistic and expensive, and it can come at the risk of poisoning a dataset with information about a different customer – all things we want to avoid. The private chef integration pattern adds a wealth of dynamic and private data to an experience by extending patterns like RAG to be more than simple vector retrieval. Use vector-based retrieval and similarity searches to deterministically identify secondary data retrieval mechanisms that are custom and bespoke for each user.
Use what works
Each of these patterns has at least one thing in common—in each of them, we’re making space for a form of governance or auditability before the model, after the model, or both.
If all we need is a way to get non-deterministic, ungovernable, unrestricted text, then we can go straight to and from the LLM. But if we’re trying to build trusted systems that use new advancements in AI effectively while protecting our customers’ privacy and our organizations’ data, try an integration pattern that breaks free from the chat paradigm and makes space for control in conjunction with LLMs.